Motivation
Recently, RLHF seems to be discussed heavily in recent conversations in AI, especially in the context of user alignment. See: an interesting Anthropic paper on alignment faking or OpenAI’s reinforcement fine-tuning video.
To better understand these conversations, I aim to achieve a satisfactory understanding of how RLHF works.
A Basic Overview
RLHF is a subfield under the broader technique of Reinforcement Learning, which optimizes a model’s performance by learning from a reward function. In RLHF, the reward function is provided via human preference. This makes RLHF a natural fit for the user alignment problems.
Use when:
- No good loss function
- Can’t easily label production data
Algorithm
- Pretrain a language model (LM)
- Train a reward model
- Fine-tune the LM with RL
1. Pretraining a Language Model
Options:
a. Train one LM from scratch b. Use pretrained LM (e.g. GPT-3) - can also perform Supervised Fine-tuning (SFT)
Supervised Fine-tuning: fine-tuning the LM with human-labeled (input, output) pairs. Considered a high-quality initializationfor RLHF.
2. Training a reward model
Collect dataset of (input, output, reward) triplets.
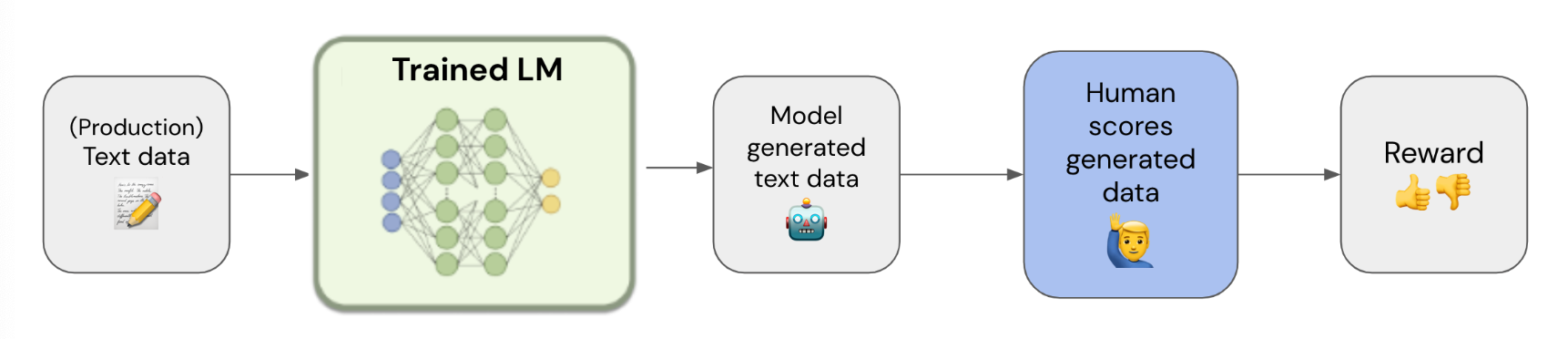
Data Collection Pipeline: Input text data –> Pass through model –> have human attribute reward to generated output
Note that reward could be a scalar value, or simply a 0/1 binary classification for a positive or negative experience.
This creates a new dataset.
With this new dataset, we can train a reward model with the objective to mimic the human’s reward labeling– doing RLHF training offline without a need for human in the loop. Input would be the same as the original dataset, but the output would be the reward.
3. Fine-tuning the Language Model with RL
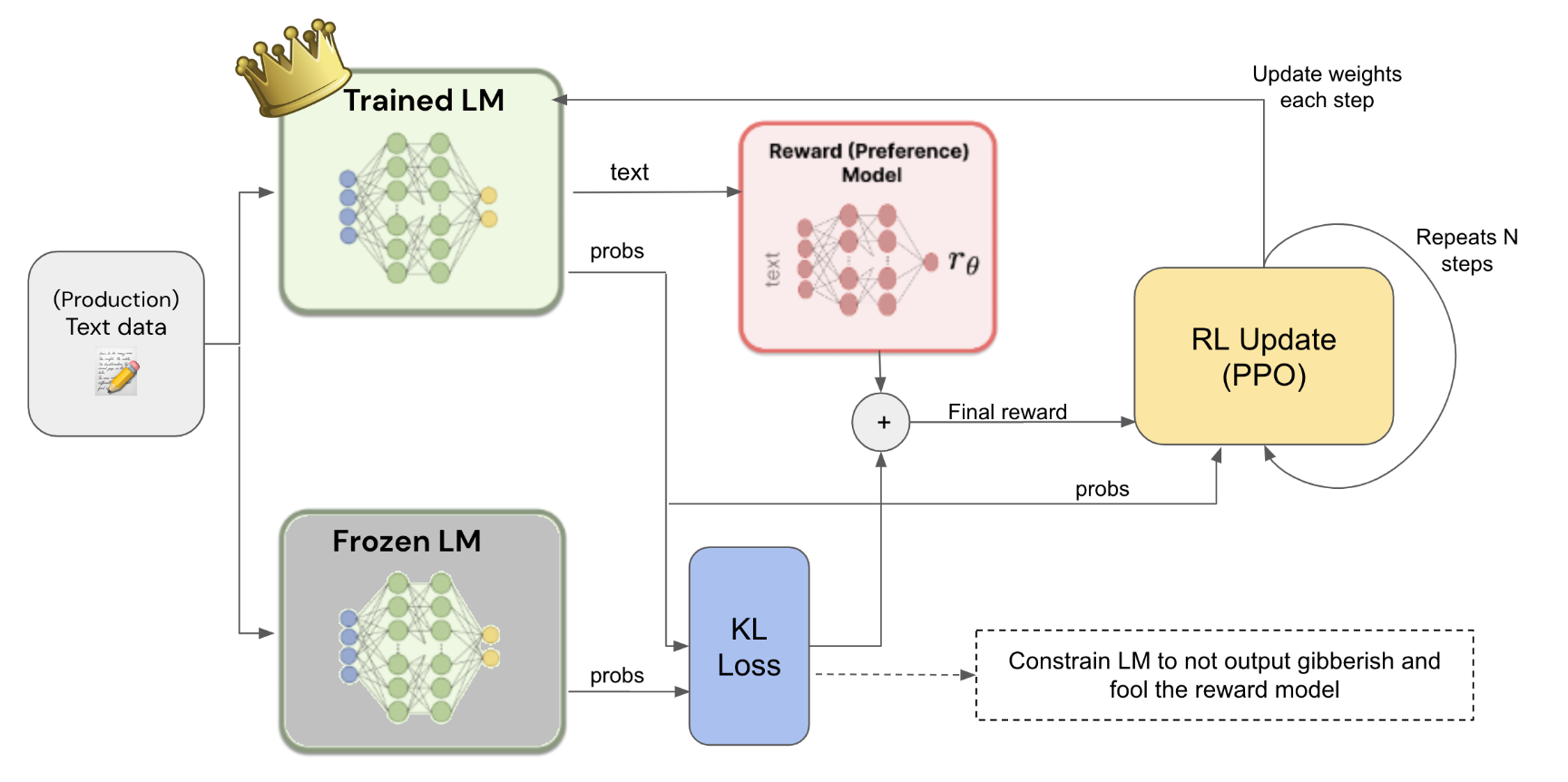
Use rewards (given by reward model from step 2) to train the main model (trained LM from step 1).
Use Reinforcement Learning to construct a loss to backpropagate to the LM (because reward won’t be differentiable).
Pipeline:
-
Make an exact copy of LM (from step 1) and freeze its trainable weights.
Creating a copy helps to prevent the (trainable) LM from completely changing its weights, thus changing its behavior (and output gibberish).
-
This is ALSO why we calculate the KL divergence loss between output probabilities of both frozen and non-frozen LM.
KL Loss is added to the reward produced by reward model. (If online learning, training model while in production, can replace reward model with human reward score directly).
-
Apply Reinforcement Learning to make reward loss differentiable
Reward isn’t differentiable because it was calculated with a reward model with input text, for example. Text is obtained by decoding output log probabilities of the LM. Decoding process is non-differentiable.
-
Make loss differentiable with Proximal Policy Optimization (PPO).

PPO algorithm calculates loss:
- Initialize: Set inital probs = new probs
- Calculate: Ratio between new probs / initial probs (output text probabilities)
- Calculate:
loss = -min(ration * R, clip(ratio, 1-epsilon, 1+epsilon) * R)- R:
reward + KL - epsilon:
~0.2 - clip: to bound ratio to be between
1-epsilonand1+epsilon - Negate (add -) because we want to maximize reward, and thus minimize negation of loss with gradient descent
- R:
- Update weights of LM through loss backpropagation
- Calculate new probs with newly updated LM
- Repeat from step 2 (up to N times)
Additional Thoughts
What’s the difference between RLHF and ICL (in-context learning) or RAG (retrieval-augmented generation)?
RLHF involves directly changing gradients via loss backpropagation.
ICL and RAG don’t directly change the model’s weights. Instead, they provide additional context to the model to improve its performance for specific tasks. ICL adds examples to the input to guide output, and RAG adds relevant documents to the input better inform output.